Understanding Data Pipelines
Data pipelines describe the sequential processes used to transform source data into data suitable for storing into target locations. The pipeline analogy illustrates the flow of data as a one way stream, which moves through various processes for cleaning and filtering but never backwards.
Raw data collected in enterprise settings can come from hundreds of internal and external sources each of which format and enforce data quality differently. Like reclamation water that must be purified by flowing through multiple scrubbers and chemical treatments before use, the enterprise’s data pipeline ensures that all raw data undergoes treatment designed to produce the same level of data quality before entering into enterprise use.

Data pipelines are a fundamental concept used in the Data Integration and Interoperability (DII) knowledge area of most data management frameworks. DII is concerned with the movement and consolidation of data within and between applications and organizations.
The general data pipeline pattern consists of data producers, data consumers, and the data pipeline that links the two. Data producers include on-premise sources, edge sources, SaaS sources, and cloud sources. Data from these sources is ingested or integrated into an operational data store where it is transformed into a format suitable to be stored in data warehouses and further used by downstream data consumers.
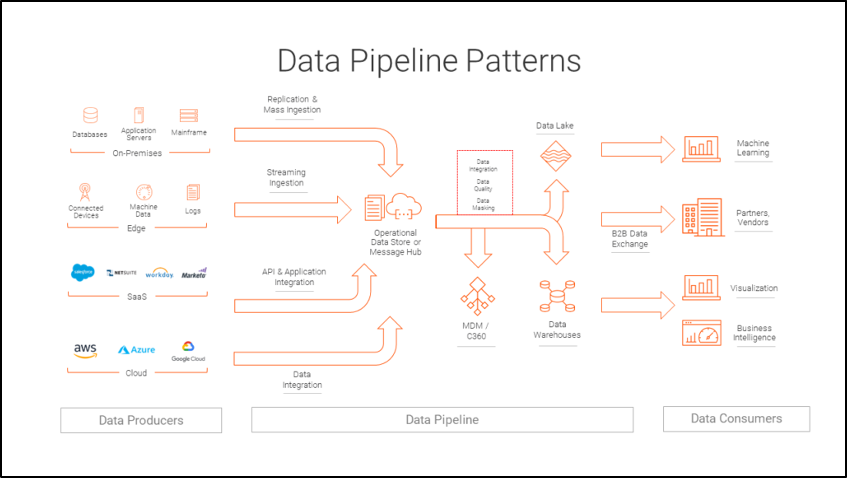
“Data Pipeline Patterns” by Informatica.com
Types of Data Sources
- On-premise sources include databases, application servers, and mainframes, many which may use SQL, Oracle, ODBC, even CSVs to store data.
- SaaS APIs are also a common data source. Application Programming Interfaces (APIs) allow systems to speak a common language, the API language, and work together without having to reveal their inner workings to each other.
- Edge computing encompasses IoT devices and peripheral systems. The Edge provides access to sensor devices away from the central system where data is processed near or on the sensor device (data processing where data is generated), in order to speed response time, for example, in cases such as in self-driving automobiles when latency risk is too great. These sources can send summary data back to central systems after local processing.
- Cloud data sources, like data exchanges, offer enterprises access to data sources beyond their reach that can be integrated into their operations, including public data sets, social media, marketing data, or partner data warehouses and data lakes.


Data pipelines are designed to form the foundation to other data projects, like:
- B2B data exchanges are industry standardized data exchanges that allow the sharing of operational data between vendor partners.
- Business intelligence and data visualizations are critical avenues for downstream data consumption, providing much needed understanding about business trends, and most importantly insight into the business itself with actionable information.
- Machine learning applications use AI techniques that automate analytical model building to construct predictive models, which anticipate questions like customer behavior patterns, and prescriptive models, which anticipate changes and risks to form recommendations to future potential business outcomes.
In short, data pipelines are patterns of data movement, but also a term that refers to the solutions employed in automating data integration and interoperations.
Types of Data Pipelines
Two common types of data pipelines are in popular use today, streaming data processing, and the ubiquitous batch processing.
Batch Processing
Most data moves between applications and organizations as files or chunks of data on request or periodically as updates. This process is known as a batch or sometimes ETL. The batch is usually very large, and requires significant time to transfer and resources to process, therefore it is often performed during off-peak hours when compute resources can be wholly dedicated to the job. Batch processing is often used for data conversions, migrations, and archiving, and is particularly useful in processing huge volumes of data in short time frames.
Batches are processed in one go which entails synchronization risks where one system that is periodically updated by batch processes becomes out of sync until the update batch is completed. But, there are many techniques to mitigate this risk, including adjusting batch frequency, using a scheduler, and the use of micro-batches.


Streaming Data
Some systems too critical to business operations cannot be subject to latency, for example, ordering and inventory systems that could be processing thousands of transactions an hour. This scenario calls for real-time, synchronous solutions. In streaming data processing, or target accumulation, the target system does not wait for a source-based scheduler, instead, it will accumulate data into a buffer queue and process it in order.
Data Pipeline Architecture
Data pipeline architecture refers to the design of the systems that form the data pipeline. Data pipelines are composed of four general components.
- Data Sources — Data sources include APIs, on-premise systems, Cloud, and Edge.
- Business Logic Rules — The actual processes and logic the business undergoes in its day to day that it needs data for. These rules are written down, but they are not computer code, instead they are used to configure the data pipeline’s filters, etc., for example, a business rule may say purchases of $500 or more must be flagged for approval before acceptance.
- Data Destination or Target Sources — Common targets are data warehouses and data lakes.
- Scheduler or Orchestration Tool — Schedulers control the frequency timing for initiating batches. An orchestration tool, or workflow orchestrator, is a overarching application that coordinates (“orchestrates”) processes and timings between several systems.


Data Pipelines vs ETL
ETL stands for Extract, Transform, and Load, and refers to the basic pattern for processing and integrating data together from multiple sources. This pattern is used in physical as well as virtual executions, and in batch processing and real-time processing. In general, ETL data flows is a term that can be interchanged with data pipeline, however, data pipelines entail more.
A data pipeline, in comparison to ETL, is the exact arrangement of components that link data sources with data targets.
For example, one pipeline may consist of multiple cloud, on-premise, and edge data sources, which pipe into a data transformation engine (or ETL tool) where specific ETL processes can be specified to modify incoming data, and then load that prepared data into a data warehouse.
Contrastingly, another pipeline may favor an ELT (Extract, Load, and Transform) pattern, which will be configured to ingest data, load that data into a data lake, then transform it at a later point. However, ETL is the more common approach rather than ELT, and so easily associated with data pipelines.
Learn how Reltio can help.